近年来,人工智能已经逐步进军工业质量检测行业,并且取得初步进展,AI在工业领域的可行性、落地性已经在工业领域各场景中得到了证实。目前质检领域大多采用深度学习中的目标检测算法。因为深度学习目标检测方向在社会上用处广泛,为生活提供了极大的便利,得到了大众广泛的认可。虽然通用性极强的目标检测算法应用在了各行各业,但是其在工业领域的弊端逐渐呈现了出来,深度学习能在自然场景中取得极大的进展不单单是算法上不断地迭代进步,与算法并驾齐驱的还有其所依赖的庞大的标注数据集。也就是说,监督算法极其依赖标注数据集,需要大量的数据供神经网络进行学习,一个好的数据集直接影响模型的精度。然而数据集收集困难是目标检测在大多数工业领域遇到的难点之一。



随着深度学习算法不断进军工业界,服务于工业领域的AI算法也将更加成熟、稳定,针对工业领域的算法与解决方案不断的涌现,其数据集也在不断收集中,且出现了异常检测算法评估数据集MVTec,在异常检测算法频繁刷榜MVTec后,相信在不久将来会广泛应用于工业领域。由于目标检测极其依赖缺陷数据集,异常检测可能在某些情形下会替代目标检测,或许两者结合才是更佳的方案。

目前,使用深度学习目标检测进行工业缺陷检测时,主要有以下缺点:
(1)缺陷未知性:由于缺陷的成像有位置、形状、光源等影响因素在,不同因素会组合成各种各样的缺陷,将使得AI目标检测算法学习起来变得异常困难。只能不断增加已知的缺陷类别,如果将来出现未知类型的缺陷类别,设备将失去其该有的作用,可能会给生产方带来损失。
(2)缺陷收集困难:缺陷数据集收集困难,人造或合成的缺陷与真实缺陷相差大,存在低质量样本数据,数据收集周期较长,可能持续推迟设备的交付日期,这使得生产方将在人力成本上继续投入,且项目前期误检漏检情况出现频繁,使得使用方对设备检测能力的信心出现动摇,这将违背深度学习在工业领域的初衷,为企业提供智能化、无人化的工厂,减小过程成本。
(3)低频缺陷拦截困难:即使是已知且数据集充足类别的缺陷,也会出现与此种类别特征不相近的缺陷,可能出现漏检情况
基于以上问题点,异常检测算法应用在工业质检行业的优势就涌现了出来,因为无监督算法的特性在,可以绕开目标检测算法在工业领域遇到的部分问题。
异常检测算法优势:
(1)异常检测是无监督算法,不需要缺陷数据集,仅需要ok数据集即可,部分异常检测算法仅需要少量ok数据集,避免了收集缺陷困难的问题。
(2)不需要对各类别各形态缺陷进行定性,避免了新类别或新特征不能检出问题,避免了难区分缺陷类别的认定。
鉴于以上问题,通过深度学习异常检测算法,避免了低频缺陷数据集收集困难,未知类别缺陷难拦截的问题,并在缺陷数据集不足的情况下,能够很好的解决检出问题。对于工业领域的零漏检的高标准要求更进一步。有效的减少了项目周期,更加快速的给企业带来生产环节上的效益增长。
异常检测:
异常是指偏离预期的事件或项目。与标准事件的频率相比,异常事件的频率较低。产品中可能出现的异常通常是随机的,例如颜色或纹理的变化、划痕、错位、缺件或比例错误。
异常检测(Anomaly Detection)也称偏差(deviation)检测或者离群点(outlier)检测,从数据的角度来看,其实就是检测出和众多其他观测值差别非常大的一个特殊的观测值。异常检测在历史上实际是数据预处理的一个步骤,但是在现代研究中越来越重要,逐渐发展为一个独立的领域。
无监督异常检测:
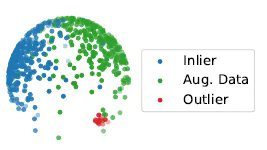
没有标签情况下,往往目标是将一个得分或标号赋予给每个数据对象。比如聚类算法,根据一些规则将数据进行无监督的聚类。简单直白地讲,如果聚类簇比较偏远,或者密度比较少,可能就是异常。类似查找图像离群点算法如孤立森林、SVM等。 但是基于检测图像中离群点是不稳定的,由于零件本身形态特性复杂,很多时候不能区分开正常点与离群点。
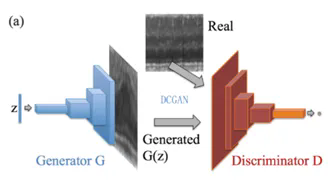
以前基于深度学习的工作主要集中在生成算法,如生成对抗网络(GAN)或变分自动编码器(VAEs) 。无监督生成模型通过学习真实数据的本质特征,刻画出样本数据的分布特征,生成与训练样本相似的新数据。模型能够发现并有效地内化数据的本质,并生成这些数据。生成式模型可以用于在没有目标类标签信息的情况下捕捉观测到可见数据的高阶相关性。
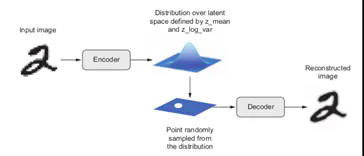
如基于生成对抗网络(GAN)或变分自动编码器(VAEs)的生成网络,在该网络中,编码器接受输入数据,并将其压缩为潜伏空间表示,然后解码器将从该空间重构输入数据。
VAE将图像转换为统计分布的参数:均值和方差。然后,VAE使用均值和方差参数随机采样分布的一个元素,并将该元素解码回原始输入。该过程的随机性提高了鲁棒性并迫使潜在空间在任何地方编码有意义的表示:在潜在空间中采样的每个点被解码为有效输出。
随着深度学习算法不断进军工业界,服务于工业领域的AI算法也将更加成熟、稳定,针对工业领域的算法与解决方案不断的涌现,其数据集也在不断收集中,且出现了异常检测算法评估数据集MVTec,在异常检测算法频繁刷榜MVTec后,相信在不久将来会广泛应用于工业领域。由于目标检测极其依赖缺陷数据集,异常检测可能在某些情形下会替代目标检测,或许两者结合才是更佳的方案。
